AWS provides an Auto Scaling service to do just that. Putting a group of auto-scaling Apache servers behind an Elastic Load Balancer creates a highly available and highly scalable infrastructure for your web application. However, EC2 instances are expensive, which raises a new problem: can you trust AWS Auto Scaling to manage your infrastructure for you?
The only way you can say “yes” to this question is if you have a clear window into your Auto Scaling activities. The ability to see how many EC2 instances you’re paying for at any given time, as well as when and why they were created, gives you the necessary peace of mind to automatically scale your web application. As in the previous article, this information can be extracted from your application’s log data.
This article takes full stack visibility one step further by adding Auto Scaling and Elastic Load Balancing to our example scenario. We’ll learn how to define key performance indicators (KPIs) that are tailored to your specific needs and monitor them with real-time dashboards and alerts. This not only aids in troubleshooting your system, but also provides the necessary insight to optimize your Auto Scaling behavior.
Scenario
This article assumes that you’re running a collection of Apache servers on auto-scaled EC2 instances behind an Elastic Load Balancer. As in the previous article, we also assume that you’re monitoring your AWS administration activity with CloudTrail.
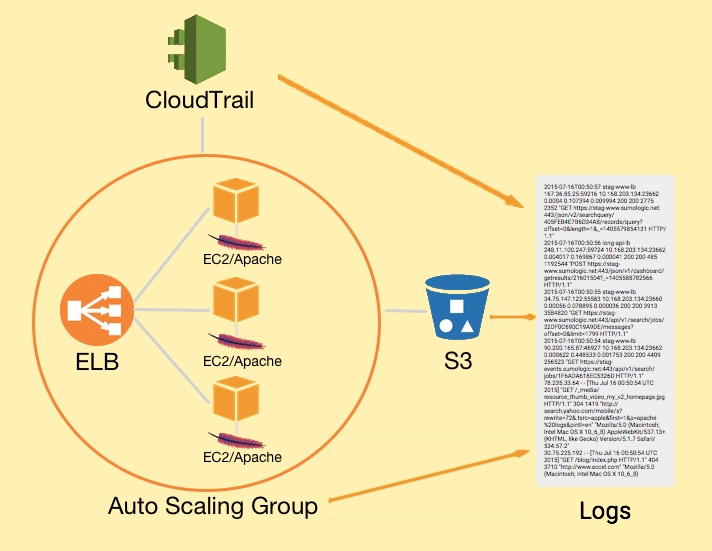
This stack is much more complicated than in the previous article. Instead of a single web server and EC2 instance, you now have an arbitrary number of them. This means that a centralized log analyzer is no longer an optional component of your toolchain—SSH’ing into individual machines and manually inspecting log files is now virtually impossible. We also have new potential points of failure: ELB could be routing requests incorrectly, your Auto Scaling algorithm could be creating too many or too few EC2 instances, and any one of those instances could be broken.
In addition, when an EC2 instance gets deleted by AWS Auto Scaling, all of those log messages disappear. If you’re not collecting those logs with a centralized tool, the information is lost forever. You have no way to see if that server caused an unnecessary EC2 creation or deletion event due to a traffic spike or an obscure error.
As your web application scales, log analytics becomes more and more important because the system is so complex you typically don’t even know when something isn’t working. As a result, you don’t know when to start troubleshooting as we did in the previous article. Instead, we need to be proactive about monitoring our infrastructure.
For instance, when you have a hundred Apache servers, you won’t notice when one of them goes down. Of course, this also means that you won’t know when you’re wasting money on an EC2 instance that isn’t having any impact on your customers. But, if we have a real-time dashboard showing us the traffic from every EC2 instance, it’s trivial to identify wasted EC2 instances.
Monitoring + Tuning: A Virtuous Cycle
Optimizing your Auto Scaling algorithm directly affects your bottom line because it means you aren’t wasting money on unnecessary resources, while also ensuring that you’re not losing customers due to an underperforming web application.
Tuning is all about correlating the number of EC2 nodes with business metrics like page load times and number of requests served. This implies that you have visibility into your operational and business metrics, which is where log analytics comes into play. Apache and ELB logs provide traffic information, while CloudTrail records EC2 creation and deletion events. Correlating events from all these components provides key insights that are impossible to see when examining the logs of any one component in isolation.
It’s also important to remember that tuning isn’t a one-time event. It’s an ongoing process. Every time you push code or get a large influx of users, there’s a chance that it will change your CPU/memory/disk usage and disrupt your finely tuned Auto Scaling algorithm. In other words, it’s not just the Auto Scaling algorithm that needs to be optimized, it’s the behavior of your entire system. Monitoring your infrastructure with proactive alerts and real-time dashboards means you’ll catch optimization opportunities much sooner and with much less effort.
In this article, we’ll learn how to monitor an AWS web stack with real-time dashboards that tell us exactly what we want to know about our load balancing and auto scaling behavior. This visibility gives you the confidence you need to let Auto Scaling manage your EC2 creation and deletion.
Customizing your KPIs
Log analytics is designed to monitor a complex, dynamic system. As your infrastructure changes, your log analytics instrumentation needs to change with it. The ability to define custom KPIs based on your unique needs is a critical skill if you want your log analytics tool to stay relevant as your application evolves.
The rest of this article walks through this process with an example AWS web stack. Remember that these queries are just a starting point—feel free to alter parameters to analyze different metrics more suited to your specific needs.
ELB Response Time
Elastic Load Balancer logs contain three types of response time metrics: time from the load balancer to the backend instance, the backend instance’s processing time and the time from the backend instance back to the load balancer. These three values give you a broad overview of how your system is performing as a whole.
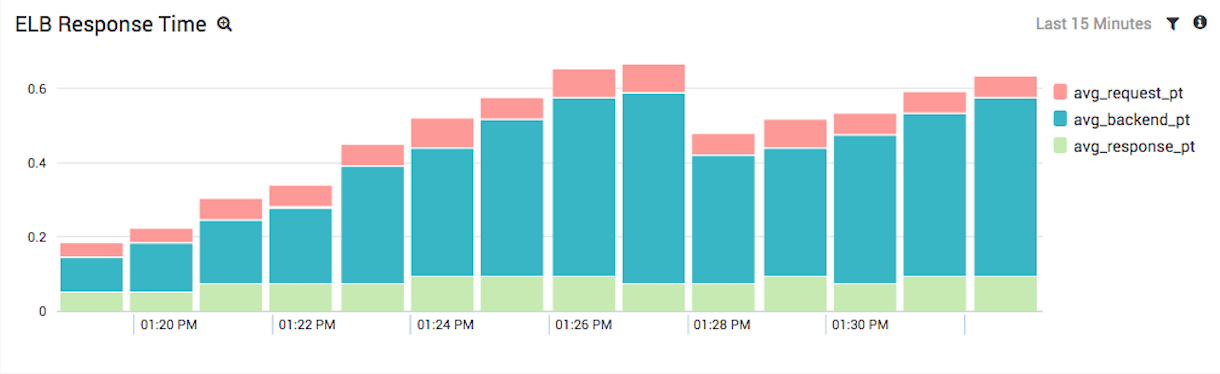
The above chart shows a spike in backend processing time, which tells you that something is wrong with your backend EC2 instances (i.e., your web servers) opposed to a problem with ELB. But, notice that this query isn’t meant to identify the root cause of a problem. It’s only a high-level window into your EC2 performance. The real value in full stack AWS log analytics is the ability to compare this chart with the rest of the ones we’re about to create.
This chart was generated with the following Sumo Logic query. The idea is to save this query as a panel in a custom dashboard alongside other important metrics like web traffic requests and the number of active EC2 instances. Having all these panels in a one place makes it much easier to find correlations between different layers of your stack.
_sourceCategory=aws_elb | parse "* * *:* *:* * * * * * * * \"* *://*:*/* HTTP" as f1, elb_server, clientIP, port, backend, backend_port, request_pt, backend_pt, response_pt, ELB_StatusCode, be_StatusCode, rcvd, send, method, protocol, domain, server_port, path | timeslice by 1m | avg(request_pt) as avg_request_pt, avg(backend_pt) as avg_backend_pt, avg(response_pt) as avg_response_pt by _timeslice | fields _timeslice, avg_request_pt, avg_backend_pt, avg_response_pt
ELB Traffic by Requests and Volume
Next, let’s take a look at the web traffic being served through ELB. The following chart shows the traffic volume in bytes received and bytes sent, along with the number of requests served:
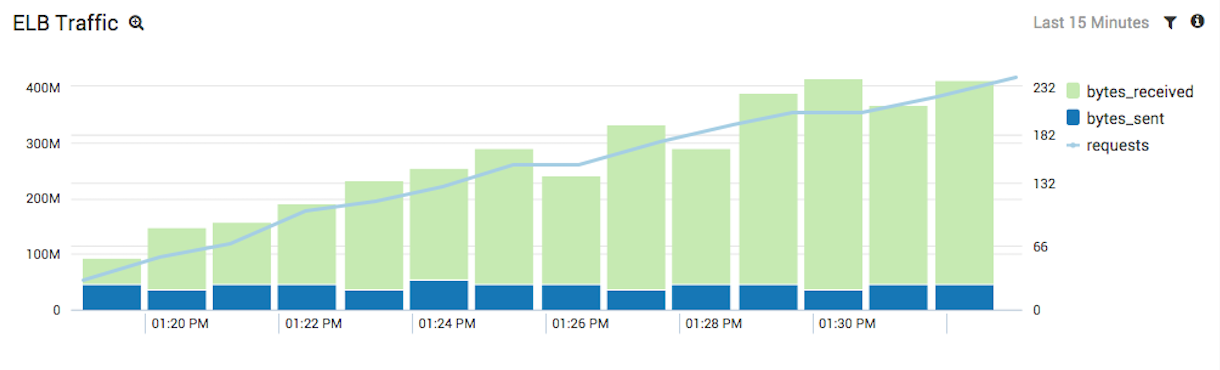
This sheds a little more light on the graph from the previous section. It seems our spike in backend processing time was caused by an influx of web traffic, as shown by the spike in both requests and bytes received. This is valuable information, as we now know that the problem wasn’t with a slow script on our web servers, but rather an issue with Auto Scaling. Our system simply wasn’t big enough to handle to spike in traffic and our Auto Scaling algorithm didn’t compensate quickly enough.
The above chart was created with the following query:
_sourceCategory=aws_elb | parse "* * *:* *:* * * * * * * * \"* *://*:*/* HTTP" as f1, elb_server, clientIP, port, backend, backend_port, request_pt, backend_pt, response_pt, ELB_StatusCode, be_StatusCode, rcvd, send, method, protocol, domain, server_port, path | timeslice by 1m | sum(rcvd) as bytes_received, sum(send) as bytes_sent, count as requests by _timeslice
One of the common metrics for defining AWS’s Auto Scaling algorithm is request frequency. This query shows you requests per minute, as well as another important metric: traffic volume. A web application serving a small number of very large requests won’t scale correctly if EC2 instances are scaled only on request frequency. This is the kind of visibility that gives you the confidence to let Auto Scaling take care of EC2 instance creation and deletion for you.
Number of Requests by Backend EC2 Instance
Both of the above queries presented average values across your EC2 infrastructure. They provide a primitive system for monitoring your Auto Scaling behavior, but you can take it a step further by identifying stray EC2 instances that aren’t working well compared to the rest of the system. The following query displays the number of requests served to individual EC2 instances.
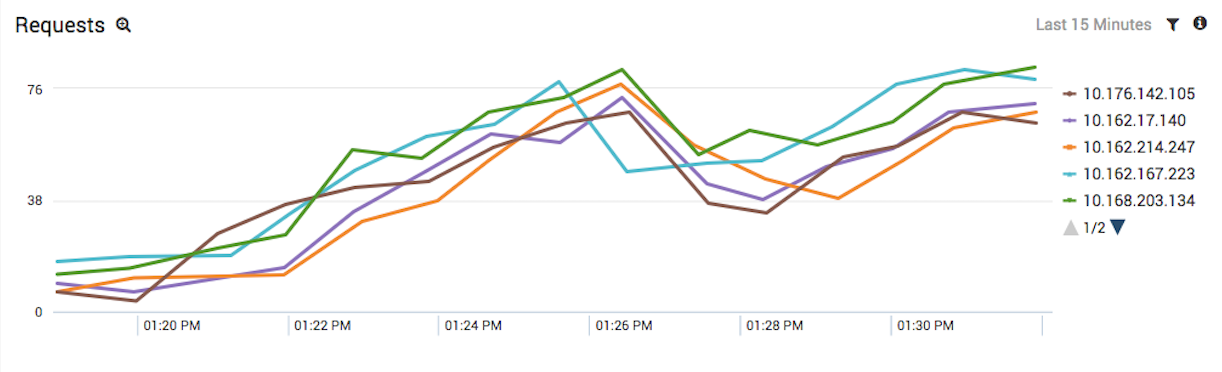
EC2 instances that aren’t serving as much traffic as the rest of the system are easily identified by lower lines on the graph. This can indicate ELB misconfiguration, large requests that take so long to serve that your load balancer stopped sending the instance new requests, or a hanging script on your web server. Whatever the reason, EC2 instances serving an unusually low amount of requests are wasting money and need to be optimized.
_sourceCategory=aws_elb | parse "* * *:* *:* * * * * * * * \"* *://*:*/* HTTP" as f1, elb_server, clientIP, port, backend, backend_port, request_pt, backend_pt, response_pt, ELB_StatusCode, be_StatusCode, rcvd, send, method, protocol, domain, server_port, path | timeslice 1m | count as requests by backend, _timeslice | transpose row _timeslice column backend
As you can see from the underlying query, we’re not actually analyzing every web server directly. Instead, we’re extracting the backend EC2 instance from each ELB log and dividing up the traffic based on that value. Since the ELB logs already have all the request information we’re looking for, this is a bit more convenient that pulling logs from individual servers. However, with a tool like Sumo Logic, analyzing logs from multiple sources isn’t that much harder. This would be useful, say, if we were looking at custom application logs instead of web server requests.
Processing Time by Backend EC2 Instance
We can get another view on our EC2 instances by analyzing backend processing time. This will identify a different set of issues than the previous query, which only looked at the number of requests, opposed to how long it took to serve them.
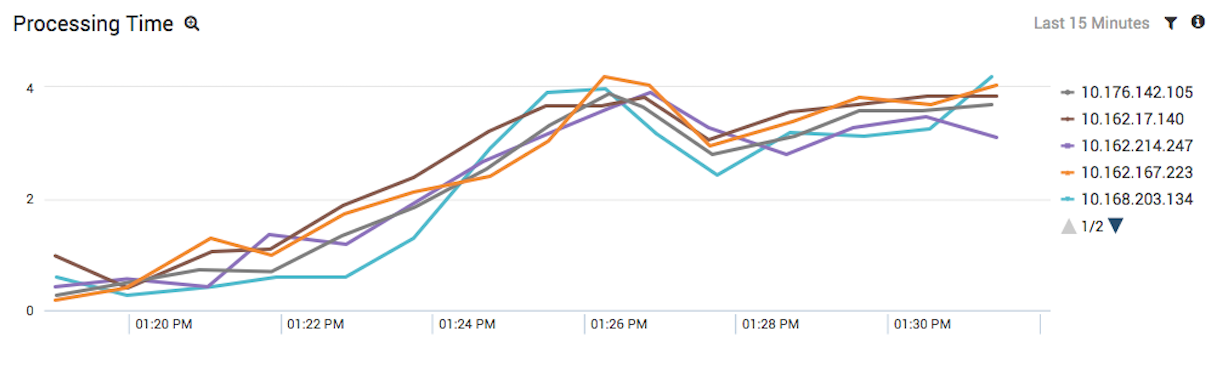
Slow instances can be caused by anything from a server running old, unoptimized code, hardware issues, or even a malicious user performing a DoS attack on a single instance. Note that many servers with high latency won’t fail a health check, so this query finds optimization opportunities that simpler monitoring techniques won’t catch.
_sourceCategory=aws_elb | parse "* * *:* *:* * * * * * * * \"* *://*:*/* HTTP" as f1, elb_server, clientIP, port, backend, backend_port, request_pt, backend_pt, response_pt, ELB_StatusCode, be_StatusCode, rcvd, send, method, protocol, domain, server_port, path | timeslice 1m | avg(backend_pt) as avg_processing_time by backend, _timeslice | transpose row _timeslice column backend
This screenshot shows that all our servers are responding more slowly to requests after the influx of traffic. It tells us that the problem is system-wide, rather than isolated in any particular server or group of servers. This is further confirmation that our infrastructure is simply too small to accommodate the influx of traffic.
EC2 Creation and Deletion Events
Now we get into the meaty part of full stack log analytics. By examining CloudTrail logs, we can figure out when EC2 instances were created or deleted. These events are incredibly important because they directly influence your bottom line.
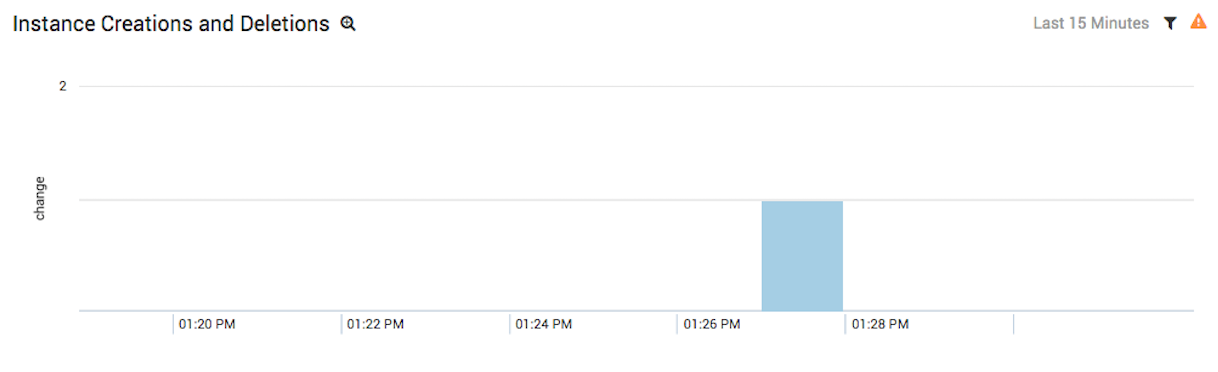
This chart shows that a single web server was allocated after the spike in traffic. It tells us that our Auto Scaling creates instances in the right direction, but not enough of them to accommodate large changes in traffic. From this, we can infer that our Auto Scaling algorithm is not sensitive enough. Our next and final query in this article will confirm this hypothesis.
The underlying query tallies up RunInstances, StartInstances, StopInstances, and TerminateInstances events from CloudTrail logs, which signify EC2 instance creation and deletion events:
_sourceCategory=aws_cloudtrail | json auto
| where eventname = "RunInstances" OR eventname = "StartInstances" OR eventname = "StopInstances" OR eventname = "TerminateInstances"
| parse regex "requestParameters\"\:\{\"instancesSet\"\:\{\"items\"\:\[(?<instances>.*?)\]"
| parse regex field=instances "\{\"instanceId\"\:\"(?<instance>.*?)\"" multi
| if(eventname = "RunInstances" OR eventname = "StartInstances", 1, -1) as instance_delta
| timeslice 1m
| sum(instance_delta) as change by _timeslice
Note that this panel is only useful when you compare it to the rest of our dashboard. Knowing that an EC2 instance isn’t really helpful, but if you can see that it was created because of an x percentage increase in web traffic, suddenly you have the means to start testing much more sophisticated Auto Scaling algorithms and validating the results in real time.
Number of Backend EC2 Instances with Requests
Ultimately, the number of EC2 instances that you have is what’s going to determine your bottom line. Pivoting this metric against other values in your log data makes sure that the money you’re spending on EC2 instances is actually impacting your user experience.
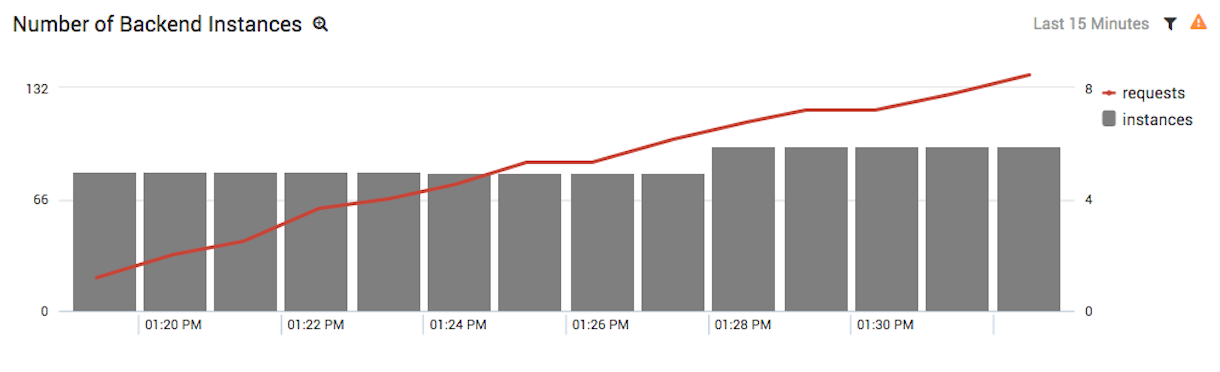
The following panel shows the total number of web requests served by your application, overlaid on the number of active EC2 instances during any given time period:
This is the holy grail of Auto Scaling monitoring. With one look at this chart, we can conclude that our EC2 instance creation isn’t keeping up with our web traffic. The solution is to tweak our Auto Scaling monitoring to be more sensitive to request frequency.
_sourceCategory=aws_elb | parse "* * *:* *:* * * * * * * * \"* *://*:*/* HTTP" as f1, elb_server, clientIP, port, backend, backend_port, request_pt, backend_pt, response_pt, ELB_StatusCode, be_StatusCode, rcvd, send, method, protocol, domain, server_port, path | timeslice by 1m | count as requests, count_distinct(backend) as instances by _timeslice
The above query extracts the number of active EC2 instances during the specified time period. You can pair this with CloudTrail’s EC2 creation/deletion events in the previous section for a more precise picture of your application’s Auto Scaling activity.
Also keep in mind that the chart from the previous section will still find optimization opportunities that this query won’t because it shows the frequency of EC2 creation and deletion events. This is valuable information, as it ensures your algorithm isn’t allocating and deallocating EC2 instances too quickly.
A Brief AWS Auto Scaling Case Study
Optimizing the number of EC2 instances supporting your web application is about finding the right balance between speed and cost. If you have too few EC2 instances, your UX might be slow enough that you’re forcing users away from your site. On the other hand, if you have too many EC2 instances, you’re wasting money on diminishing returns.
We’ll conclude this article with what to look out for when it comes to tuning your AWS Auto Scaling algorithm. Notice that it would be very difficult to identify either of the following scenarios without the custom dashboard that we just set up.
Auto Scaling Not Sensitive Enough
This is the scenario that we’ve been using throughout this article. When your Auto Scaling algorithm isn’t sensitive enough, you’ll see continuous increases in backend processing time, request frequency, and/or traffic volume that aren’t recuperated by new EC2 instances. The panels in the following dashboard show a typical scenario of Auto Scaling not responding quickly enough to a growing audience:
Again, looking only at the EC2 creation events in isolation won’t tell you if your Auto Scaling is actually working. When traffic spiked, we still had a creation event, which would seem to tell us that our algorithm is working. However, further examination clearly showed that we didn’t create enough new instances to accommodate the traffic.
Auto Scaling Too Sensitive
On the opposite end of the spectrum, you can have an AWS Auto Scaling algorithm that’s too sensitive to changes in your traffic. An optimized algorithm should be able to absorb temporary spikes in traffic without creating unnecessary EC2 instances. Consider the following scenario:
Instead of a continuous increase, this dashboard shows a brief spike followed by a return to baseline traffic volume. The two top-left panels tell us that this triggered the creation of a new server, but that server stuck around after the spike subsided.
To optimize this algorithm, you can either make it less sensitive to changes in traffic so that a new server is never created, or you can make sure that it’s sensitive in both directions. When usage drops back down to normal levels, Auto Scaling should delete the extra EC2 instance that is no longer necessary.
Conclusion
AWS Auto Scaling is about trust. This article demonstrated how log analytics facilitates that trust by reliably monitoring your entire AWS web application. We set up a dashboard of custom KPIs tailored to monitor our specific stack. With one look at this dashboard, we had all the information required to assess our AWS Auto Scaling behavior.
However, Auto Scaling is only one use case for log analytics. The value of a tool like Sumo Logic comes from its ability to find relationships between arbitrary components of your IT infrastructure. In this article, we found correlations in our ELB logs, CloudTrail, EC2 instances, and Auto Scaling behavior, but this exact same methodology can be applied to other aspects of your system. For instance, if you added Amazon CloudFront CDN on top of our existing infrastructure, you might find that a particular group of mis-configured backend servers are causing cache misses.
The point is, full stack log analytics lets you find ways to optimize your infrastructure in ways you probably never even knew were possible. And, since you pay for that infrastructure, these optimizations directly affect your bottom line.
Complete visibility for DevSecOps
Reduce downtime and move from reactive to proactive monitoring.
